The Markram Interviews Part Three: The Blue Brain Project


Complete the form below to unlock access to ALL audio articles.
In the final part of our exclusive interview series with Blue Brain Project Founder and Director Professor Henry Markram, we discuss the goals that he has strived towards over the last 15 years – simulating the mouse, and eventually human, brain. We discuss the Blue Brain Project’s achievements and setbacks and Markram explains what he feels are the Project’s most surprising findings. Finally, we look towards the future – when will we have simulated the human brain? Find out more about our Markram Interviews series here.
Ruairi Mackenzie (RM): You said in your 2009 TED lecture that you will build the brain in 10 years. Have you failed?
Henry Markram (HM): We have not yet completed building a complete digital brain. We have, however, passed most of the key milestones that bring us now very close to this goal. There are many reasons why the brain has not been reconstructed in 10 years. We anticipated that massive amounts of experimental data would become openly available because of the open science revolution. I had hoped for a rapid adoption of open science where all neuroscientists would begin depositing and sharing their data in databases and where international informatics organizations would reach consensus on how to label neuroscience data and establish standards for archiving; there has been a lot of progress in this area, but we are still far from a global standard. I had also hoped for a collective excitement to join in and build the brain together.
What is important is that what the media made of the goal and what the actual scientific goals we have on the grants are quite different. The statements I made were intended to be more vision statements of what we would like to do. For example, the actual Blue Brain and original Human Brain grants specified a set of scientific milestones with tasks and work-packages that explained scientifically how we will reach these milestones. It also explained how detailed the reconstructions will be, how they will be tested and what we hope to learn from them.
The Blue Brain’s scientific roadmap is reviewed by independent scientists who verify on a regular basis if we are on track. When circumstances change as science and the world around us evolves, we make amendments and they become reviewed as well. So, while we haven’t done it in ten years, we are moving steadily according to our scientific milestones.
RM: You mentioned the Human Brain Project, which is a large collaboration with many different disciplines. If you launched such an endeavor again, what would you do differently?
HM: When you launch such a massive collaboration spanning many disciplines and almost all European countries, with hindsight, any one person would do many things differently. I would do more to counter the media hype about the goals of the project, with details about the actual science and milestones of the project. I would work more on explaining why it is so urgent that we need a wake-up call for a global action, a race. Although I thought it was obvious that this project would rely on and treasure experimental data more than any modeling project in neuroscience, I would try to emphasize more clearly that simulation neuroscience does not replace animal experiments, but is complementary to it and would highlight how in neuroscience we need all the data we can get.
I would also have worked harder to explain that simulation neuroscience can bring fresh money to neuroscience from the information and communications technology (ICT) research areas and we could in fact start benefiting from and synergizing from this massive and highly collaborative community.
I did tell my colleague scientists in the HBP that this was seed funding, but the immediate funding was more important. I was perhaps too impatient. I felt that the burden for brain diseases was at a critical stage. The burden is approaching 10% of worldwide GDP and despite all the incredible advances in neuroscience, we did not seem to be able to effectively translate these advances into new treatments – this problem remains unsolved and we still lack a strategy to turn this around. I do believe we need to challenge ourselves to take on the impossible, especially in science where there is no fundamental reason why we can’t push past the frontiers.
The positive side is that this did trigger multiple national brain initiatives, which is good news for everyone. We should also keep in mind that no big science project knows all the obstacles lying ahead when one starts, but a timeline is important to force one to examine what it will take to get there within such an ambitious timeline. We learn a lot just through such an exercise. For example, we did develop a plan of how a digital brain can be built mainly from genetic information as described in the figure below. These are broad stroke strategies, but they give a clear guidance of a new way we can tackle such a seemingly impossible challenge.
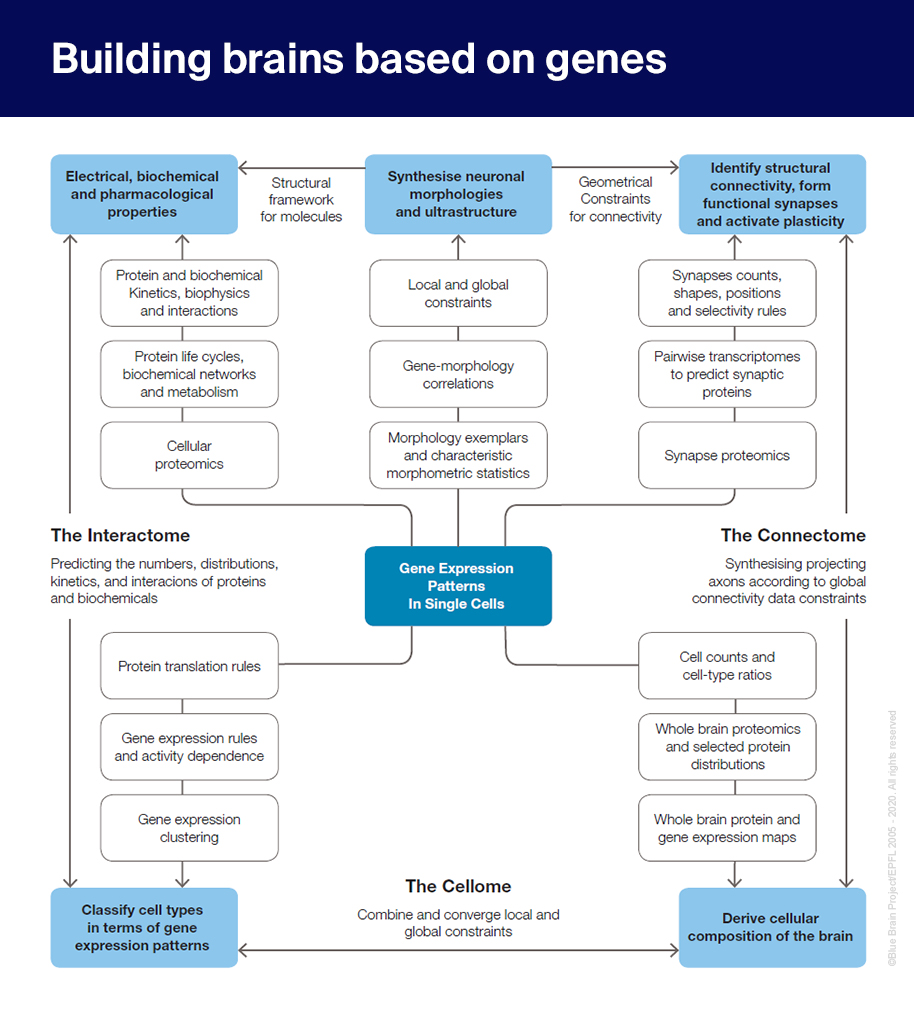
Figure 1 Building brains based on genes: from single cell transcriptomes to molecular interactions within cells (the interactome), cell types present in the brain (the cellome) and connections between neurons (the connectome).
RM: Back to the Blue Brain Project, which has now been running for nearly 15 years. What impact do you think it has had on neuroscience?
HM: Objective metrics of impact include 170 published papers to date - 25 papers in 2019. These papers are frequently cited and have thousands of views. The 2017 paper, ‘Cliques of Neurons bound into Cavities Provide a Missing Link between Structure and Function’ for example has been viewed over 270,000 times. The project has released over 31,000 model neurons, over a million data traces (via the Channelpedia and the NMC Portal) and millions of predicted missing data in its web portals. These portals have been referenced in published papers and to date, the NMC Portal has been accessed more than 130,000 times by 26,000+ users. We have released over 120 open source repositories on GitHub as well as nine major libraries. We developed a MOOC series, which to date has seen over 15,000 student registrations. We held over 70 public dissemination and outreach events in 2019.
The start of 2020 has already shown how two of our collaborators have used the digital reconstructions we have developed to make new scientific discoveries. Working with scientists at the Hebrew University of Jerusalem, together, we formulated a unique analytical approach to the challenge of reducing the complexity of neuron models while retaining their key input/output functions and their computational capabilities. ‘Neuron_Reduce’ is a new computational tool that provides the scientific community with a straightforward capability to simplify complex neuron models of any cell type and still faithfully preserve its input-output properties while significantly reducing simulation run-time.
Meanwhile, an international research collaboration with the Florey Institute, has uncovered evidence that a common neurotransmitter can selectively regulate the excitability of neurons.
RM: What are the scientific milestones the Project has passed and why are they important?
HM: Our very first scientific milestone was to be able to automatically reconstruct the electrical behavior of any neuron recorded in the brain. We passed this milestone in 2007 and have a series of publications on this approach. We accordingly released the software to allow others to model neurons. This approach and software have become the standard for many who model neurons. This was an important milestone because it allows us to automatically capture the realistic behavior of millions and even billions of neurons; an essential step to building a whole brain, which has approximately a hundred billion neurons.
The second milestone we passed was an algorithm that can recreate the connectome of a microcircuit of neurons. This algorithm allows us now to capture the way that neurons are connected in the brain and the 3D location of millions of synapses. This is important because we can, for the first time, use a model to study how a neuron processes all the different types of inputs it receives, and we can begin understanding how the connectome shapes the function of a microcircuit.
The third milestone was to bring the different types of neurons and synapses together as a microcircuit, which was demonstrated in the form of the most biologically realistic copy to date of a neocortical microcircuit – the “CPU” of the neocortex. This was important because it demonstrated the extent to which and the accuracy one can predict missing data, because it revealed the first glimpse of the cellular and synaptic map of the most complex microcircuit in the mammalian brain, and because it provided a proof of concept, for building larger circuits such as brain regions.
The fourth milestone was to validate and explore the emergent dynamics of the microcircuit in milestone three. The model gave rise to a whole range of states, solely by integrating measurements. This was a key milestone because it showed, for the first time, that we could integrate all available data about a cortical microcircuit into a digital reconstruction that would give rise to a complex array of network states comparable to that observed in real circuitry. We could use this model to simulate the transition between states by changing ionic concentration or conductance. As we can already compute the electrical field generated by all the elements in this circuit, this milestone paves the way for bridging between subcellular, cellular and synaptic activity and the electroencephalography (EEG) waveforms measured in the lab and clinic.

Close-up of synthesized neurons in a digital reconstruction of the cortex. Credit: Copyright © 2005-2020 Blue Brain Project/EPFL. All rights reserved.
The fifth milestone we passed was to solve a decade-old problem of mathematically growing the shape of neurons (their morphology). We needed to reach this milestone because normally one can only use neurons that are recorded in the brain in the laboratory and 3D digitally drawn under a microscope; this can never yield enough neurons to build a whole brain model. This milestone is also important because it provides us with a new way, in the future, to build neurons by reading genetic information. For example, in the future, we may be able to study the effect of genetic changes in the brain in terms of how they affect the shapes of neurons.
The sixth milestone we passed was to validate that the methods developed to build microcircuits can be generalized to building a brain region with curved shape and differences in cellular composition and synaptic properties. Here we targeted the somatosensory cortex for which a paper is in preparation. This was an important milestone because it demonstrated that the principles we had developed to reconstruct the microcircuitry can be extended to a much larger region -around 2 million neurons.
The seventh milestone we passed was an algorithm to connect the 11 million or so neurons in the mouse neocortex. This was a very challenging milestone because the data was very sparse. There existed some tracing data on which parts of the neocortex connect to which other parts, that we used to find a set of rules, that allowed us to predict the formation and location of 88 billion synapses that connect these neurons. This was an important milestone, because we can now build all the brain regions making up the neocortex. It also demonstrates how completely surprising and novel solutions can be found using very sparse experimental data and it reveals a number of interesting principles of how every neuron is connected in the neocortex. Passing the milestone allows us now to build the first digital reconstruction of the entire neocortex.
The eighth and ninth milestones were to validate that our algorithmic reconstruction approach works outside of the neocortex, which we tested by reconstructing the thalamus and hippocampus, with publications in preparation. These milestones were important because they meant that the processes and algorithms that we had developed for the neocortex also work, with some adaptation, for other brain regions. The specific adaptations taught us about different principles operating in their different brain regions.
Our tenth milestone was to build a full cell atlas of every neuron and glial cell in the whole mouse brain. We published and released this atlas for the community to use in 2018. This milestone sets the scene for our eleventh milestone where we will grow all the neuronal morphologies, capture all the different electrical behaviors of each type of neuron and connect all the neurons to build the first draft of the whole mouse brain by 2024-2028.
In summary, so far, we have established a solid approach to feasibly reconstruct, simulate, visualize and analyze a digital copy of brain tissue and the whole brain. How to do this was not at all obvious when we started, now it is. The road ahead is clear. This foundation took a long time to develop. It consists of solving how we database the brain, how we algorithmically and automatically build the brain in its digital form and how to simulate, visualize and analyze such a complex system. This involved building a huge ecosystem of software, discovering and developing many algorithms that can exploit interdependencies and establishing rigorous standard operating procedures that we must follow to build a digital copy of the brain. We can now start seeing what data key and what data is not. We now have clear processes in place to begin testing data reported from anywhere in the world. We have processes in place that can exploit the interdependencies. We are now at the stage where we can accelerate the building of larger brain regions and integrate more biological detail.
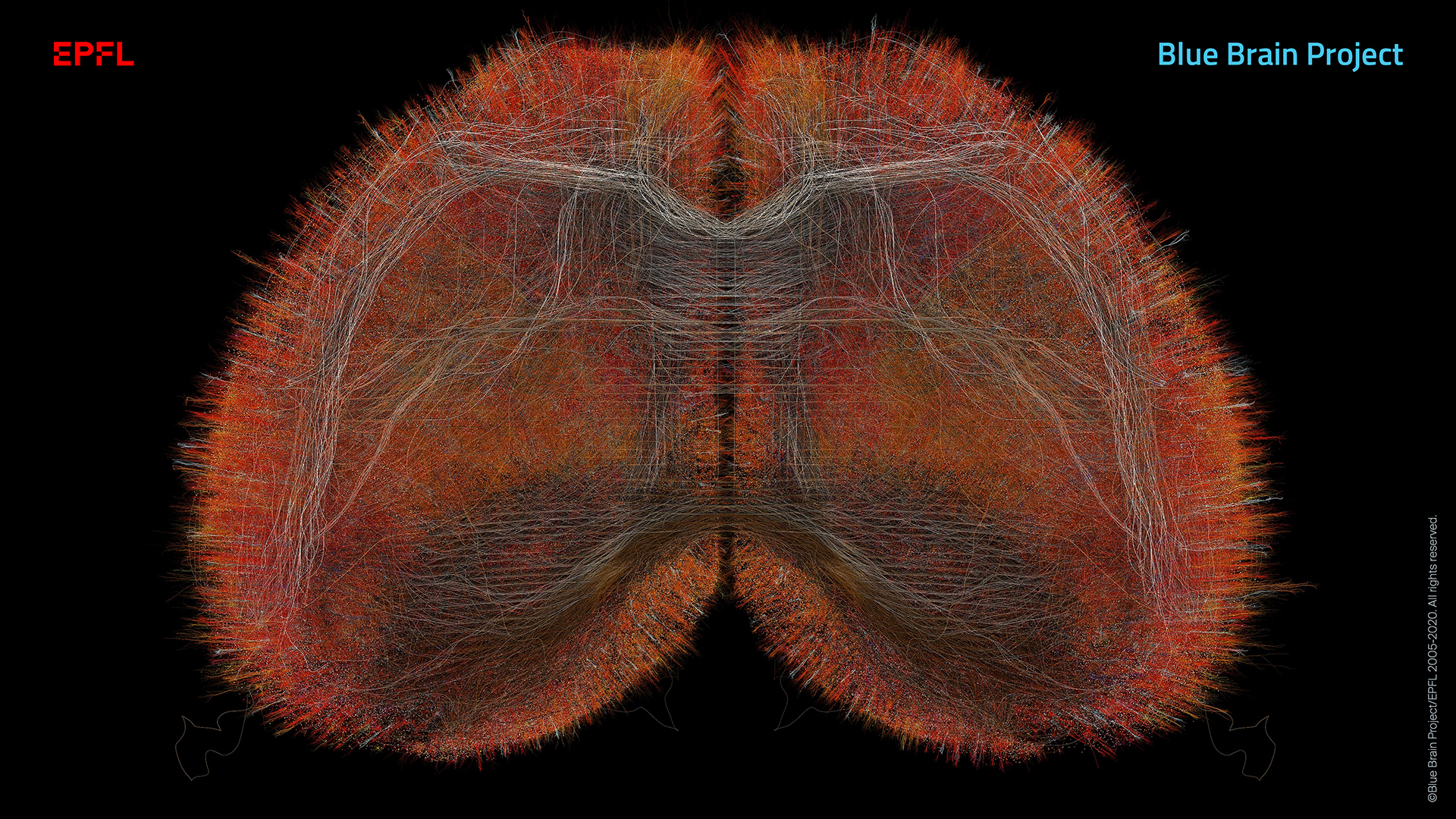
A digitally reconstructed isocortex with a simulation of synthesized white matter. Credit: Copyright © 2005-2020 Blue Brain Project/EPFL. All rights reserved. Experimental data from synthetized cells from Lida Kanari, Blue Brain Project. White matter data, courtesy of the Allen Institute for Brain Science - https://alleninstitute.org/what-we-do/brain-science/.
RM: What data, models and software has the Blue Brain shared with the community?
HM: We make Blue Brain tools, data and model parameters open source and we make all the data we obtain and gather and organize from others publicly available. For example, in 2019, we concluded a six-year study where we mapped the kinetic behavior of the largest family of ion channels: Kv channels. At the same time that the paper was published, we provided open access for research and all other non-commercial purposes to over a million Kv channel recordings. All these experimental data are publicly available for download on a dedicated, wiki-like platform called Channelpedia or via the Blue Brain Portal. This map of ion channel data will allow us to build very accurate neuron models and screen for new drugs for the brain in the future.
Opening the models for outside investigation is important because it provides all the predictions of biological parameters and also because the community can find mistakes that we could not find. That helps us improve the models in the next iteration. All the models are constantly being improved.
Over the years, we have consistently released models, data, tools, software and Massive Open Online Courses for public use. The Blue Brain Portal, released in 2018, brought all of these under one umbrella, providing a knowledge space for simulation neuroscience, which is open to everybody. The Portal also enables us to share some of the visualizations of the immense complexity of the brain.
In order to organize the massive amounts of data, we developed and released Blue Brain Nexus – open-source software that we use to manage all the data, models and literature needed to build and simulate brain circuitry.
In addition to the above, in 2011, the Blue Brain Project conceived, founded and won the grant to launch the European Human Brain Project (HBP). Even though the HBP has refocused its efforts, it is doing considerable work gathering the data for brain research and developing some important informatics tools. This is money for neuroscience that would not otherwise have existed, since it came from the budgets of the computing science side of the European Commission’s budgets, and it is now distributed to over 100 universities across Europe working on the brain.
At Blue Brain, we also have an extensive outreach program and strive to contribute to the community in many ways, such as encouraging children to continue studying STEM subjects in school. In 2019 alone, we held over 70 events from welcoming local schools, international study programs, NGOs, our second conference on chemical modulation of the brain and the public Blue Brain Seminar Series in Neural Computation. This year, we were set to hold our first school in Simulation Neuroscience, where we would begin training the next generation of simulation neuroscientists. We have had to move the school to 2021 due to the global pandemic.
RM: What was your biggest surprising insight over the years?
HM: That is a difficult question. As an experimental neuroscientist myself, I found that I was constantly surprised to see how the pieces come together and can be explained by relatively simple principles. For example, I studied synapses, their connections and how they learn in my early career. The way neurons connected with each other was so complex. Even with my optimism, I struggled to see how we will solve the challenge of connecting so many neurons in a biological way. I was trained to believe that a neuron chemically attracts the fibers of another neuron to form connections. It turns out that most of the connectivity between neurons is driven by statistical accidents between the branches of neurons. There are some, but very few exceptions to this simple rule, that will require chemical attraction and repulsion, but most of it is accidental. Then I was surprised to see that these accidents are what makes our connectomes actually very similar even when we have large differences in the sizes of our brains and the number of neurons. These accidents also make the circuits very stable to damage.
Another very rewarding insight came when we introduced an old field of mathematics to neuroscience for the very first time. We began working with algebraic topologists to understand the design of the connectome and to ask how it shapes the activity that emerges in the brain. We published a paper that received over 270,000 views and downloads. This paper showed that there are some weird and wonderful mathematical structures in the connectome and that these structures shape how the brain will react to stimuli. The implications of this study are far reaching because it suggested that we cannot see the full picture of what the brain is doing if we don’t use the right kind of mathematics. In a way, we are like flatlanders trying to understand 3D shapes.
RM: The Blue Brain is focused now on the mouse brain. When will you start on the human brain?
HM: The Blue Brain Project has focused on the rat and now the mouse brain to pioneer simulation neuroscience, establish the tools and processes and gather the data, develop the analysis to infer parameters and the software to simulate such complex models. Naturally, the human brain also has many differences, but the process of building a mammalian brain is the same. We need to practice the method on the mouse brain so we can work out what the minimal data is that we need, because there is far less data for the human brain. It will however take a new phase of this project to begin reconstructing the human brain. From a computing perspective, we need a computer that is 1000x more powerful than the one we are using, which is of course not the biggest one existing. Nevertheless, addressing the human brain will require every trick in the box with Moore’s law slowing down and it is not yet on the Blue Brain’s roadmap. Nevertheless, we are guided by this future inevitability and are developing everything with this goal in mind.

